INTREPIDO fornisce all’utente un ambiente operativo per lo svolgimento della comparazione forense della voce, con approccio automatico.
Gli utenti principali del software sono gli operatori nel settore investigativo e giudiziario: periti, consulenti tecnici, personale della polizia giudiziaria e delle forze dell’ordine in generale.
Nella versione corrente, il software INTREPIDO si avvale dell’estrazione di caratteristiche delle registrazioni vocali dette “embeddings”, attraverso un componente che implementa una rete neurale di tipo ECAPA-TDNN (Emphasized Channel Attention, Propagation and Aggregation – Time Delay Neural Network). Le caratteristiche di questa rete neurale sono descritte rispettivamente in Desplanques et al. (2020). La prima pubblicazione internazionale in cui la stessa rete neurale è impiegata nel campo della comparazione forense della voce è degli autori: Sigona & Grimaldi (2024).
Metriche per il controllo dell’affidabilità della comparazione
Le metriche di valutazione maggiormente utilizzate per descrivere le prestazioni del sistema sono sia numeriche che grafiche.Le metriche numeriche considerate sono le seguenti (cf. Brümmer e du Preez, 2006; van Leeuwen e Brümmer, 2007; González-Rodríguez et al., 2007; Morrison, 2011; Drygajlo et al., 2015; Meuwly et al., 2017).
Metriche numeriche: CLLR (log-likelihood ratio cost): pooled, mean; discrimination loss; calibration loss; Intervallo di credibilità (IC) al 95%; Equal Error Rate (EER)
Grafici: Calibration Plot, Tippett Plot; DET (Detection Error Tradeoff) Plot- Receiver Operating Characteristics (ROC) Plot; Validation Scatter plot; Empirical Cross Entropy (ECE) plot
Per ulteriori informazioni sul software: impavido@biometriaforense.it
Approfondimenti:
- Cllr.pooled (Log likelihood ratio cost): un parametro numerico che riassume la qualità complessiva del sistema, dato dall’Eq. (1)
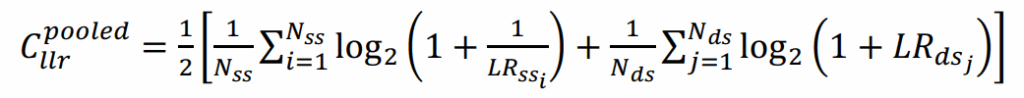
LR.ss sono i valori del rapporto di verosimiglianza nel caso di confronto tra lo stesso parlante, mentre LR.ds sono i valori del rapporto di verosimiglianza nel caso di confronti tra parlanti diversi. Poiché valori di LR.ss molto superiori a 1 supportano meglio l’ipotesi dello stesso parlante, e valori di LR.ds molto inferiori a 1 supportano meglio l’ipotesi di parlanti diversi, valori più piccoli di Cllr.pooled indicano prestazioni migliori. Al contrario, un sistema che non fornisce informazioni utili e risponde sempre con un rapporto di verosimiglianza di 1 avrà un valore di Cllr.pooled pari a 1
- IC al 95% (Intervallo Credibile al 95%): una metrica di precisione (affidabilità) dell’output del sistema. Misura la variabilità dei valori risultanti del rapporto di verosimiglianza multipli quando una registrazione del parlante in questione viene confrontata con tutte le registrazioni disponibili (se presenti) appartenenti allo stesso parlante (che può essere lo stesso del parlante in questione o un altro). Questa metrica verrà calcolata utilizzando la procedura parametrica descritta in Morrison(2011), ed è riportata su una scala di ± ordini di grandezza (= scala log10).
- Cllr.mean (likelihood ratio cost, costo del rapporto di verosimiglianza, solo accuratezza):è una misura dell’accuratezza (validità) dell’output del sistema. Secondo Morrison e Enzinger, 2016, “questo è lo stesso della metrica Cllr.pooled, ma mentre tutti i risultati dei test sono stati aggregati per calcolare Cllr.pooled, per Cllr.mean i calcoli sono stati eseguiti sulle medie dei gruppi definiti nella descrizione della metrica IC al 95%” (un gruppo è costituito dai valori risultanti dei rapporti di verosimiglianza multipli come descritto sopra).
- Cllr.min (discrimination loss, perdita di discriminazione,): una misura della qualità della fase di estrazione dei vettori di embeddings, cioè della qualità degli score punteggio. È un Cllr calcolato dopo che i valori di LR dai risultati dei test sono stati ottimizzati utilizzando la procedura non parametrica pool-adjacent-violators (PAV), che comporta l’addestramento e il test sugli stessi dati. Pertanto, questa metrica non è rappresentativa delle prestazioni attese quando vengono inseriti nuovi dati di test nel sistema. Secondo Meuwly et al. (2017), il potere di discriminazione rappresenta la capacità di distinguere tra confronti forensi in cui sono vere diverse proposizioni.
- Cllr.cal (calibration loss, perdita di calibrazione): è uguale alla differenza Cllr.pooled -Cllr.min. È una misura della qualità della fase di presentazione, cioè della calibrazione del rapporto di verosimiglianza.
- EER (Equal Error Rate): un’altra metrica ampiamente utilizzata per valutare il potere discriminante del sistema. I valori del test dei rapporti di verosimiglianza possono essere combinati con alcune probabilità a priori per ottenere probabilità a posteriori; a loro volta, le probabilità a posteriori possono essere confrontate con una soglia per classificare un confronto di test come stesso parlante (ipotesi del pubblico ministero) o parlanti diversi (ipotesi della difesa). In questo modo, i tassi di errore di falsa “identificazione” e di falso “rifiuto” possono essere calcolati come proporzione delle classificazioni errate. L’EER si ottiene regolando le probabilità a priori e la soglia in modo tale che i due tassi di errore siano uguali, e il tasso di errore risultante è chiamato EER.
Bibliografia essenziale
Brümmer, N., & Du Preez, J. A. (2006). Application-independent evaluation of speaker detection. Computer Speech & Language, 20(2–3), 230–275. https://doi.org/10.1016/j.csl.2005.08.001
Desplanques, B., Thienpondt, J., Demuynck, K., 2020. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification. In: Proc. Interspeech 2020, pp. 3830–3834. https://doi.org/10.21437/ Interspeech.2020-2650.
Meuwly, D., 2001. Reconnaissance De Locuteurs En Sciences forensiques: L’apport D’une Approche Automatique. University of Lausanne PhD dissertation.
Meuwly, D., Ramos, D., & Haraksim, R. (2017). A guideline for the validation of likelihood ratio methods used for forensic evidence evaluation. Forensic Science International, 276, 142–153. https://doi.org/10.1016/j.forsciint.2016.03.048
Morrison, G.S., 2010. Forensic voice comparison. In: Freckelton, I., Selby, H (Eds.), Expert Evidence. Thomson Reuters, Sydney, Australia, p. 99. ch. https://expertevidence.forensicvoice-comparison.net
Morrison, G. S. (2011). Measuring the validity and reliability of forensic likelihood-ratio systems. Science & Justice, 51(3), 91–98. https://doi.org/10.1016/j.scijus.2011.03.002
Morrison, G. S., & Enzinger, E. (2016). Multi-laboratory evaluation of forensic voice comparison systems under conditions reflecting those of a real forensic case ( forensic_eval_01 ) – Introduction. Speech Communication, 85, 119–126. https://doi.org/10.1016/j.specom.2016.07.006
Parzen, E., 1962. On estimation of a probability density function and mode. Ann. Math.Stat. 33 (3), 1065–1076. https://doi.org/10.1214/aoms/1177704472
Sigona F., Grimaldi M., Evaluation of Emphasized Channel Attention, Propagation and Aggregation in TDNN based automatic speaker recognition software under conditions reflecting those of a real forensic voice comparison case (forensic_eval_01). Speech Communication, 2024, ISSN 0167-6393. DOI: 10.1016/j.specom.2024.103045